BlazeHtml: Initial results
Published on April 28, 2010 under the tag haskell
What is this
This is a blogpost version of a talk I recently gave at the DutchHUG, about BlazeHtml, a “blazingly fast HTML combinator library”. This project was accepted for Google Summer of Code, so I thought I’d blog it, too.
What is BlazeHtml
About one month ago, a discussion took place on the Haskell web-devel mailing list. In the mail I link too, Chris Eidhof describes what he wants to see in the Haskell web-devel neighbourhood. Not much later, a ticket is created for Google Summer of Code by Johan Tibbel.
I was quite interested in this idea from the start, so because I was attending ZuriHac, I started a project on GitHub to do some work in this direction.
This project turned out to be more popular on ZuriHac than I had initially expected – I got the help from 7 awesome Haskellers: Chris Done, Fred Ross, Jim Whitehead, Harald Holtmann, Oliver Mueller, Simon Meier and Tom Harper.

Together, we produced an initial, prototype version of BlazeHtml. We focused on abstraction as well as performance… and I’m afraid we wanted to do too much at once. With pain in my heart, I had to throw a lot of code away and make a fresh start after ZuriHac. But this does not mean the code we wrote was not useful: I will reintegrate big parts of it later, and it was a very useful learning experience.
The actual problem
Let’s define the actual problem more precisely. We want to write abstract
descriptions of Html documents built from content and atttributes represented
both as String as well as Data.Text values, since both types are common
representations of sequences of Unicode characters in Haskell programs.
We want to render these documents to a sequence of bytes represented as a lazy
ByteString. The chunks of such a lazy ByteString should be “big enough” in
order to be efficient in later progressing, like sending the render
over a socket or writing it to a file.
For now, we fix the output encoding to UTF-8, for two reasons:
- We first want to get a performance baseline. This way we can precisely determine what later abstractions cost.
- UTF-8 supports Unicode and is widely used and recommended for web pages.
Current state
So, what is the current state of our library? After having tried different design paths, we now have an implementation that is fast. With this baseline performance, I hope to continue. The question, of course, is how fast it exactly is.
The “Big Table” benchmark is a very simple microbenchmark, implemented in many
different templating engines. It times the rendering of a big <table>. This
table has 1000 rows and 10 columns, and every row has the simple content 1, 2,
3, … 10.
The different templating engines tested are:
- Spitfire
- ClearSilver
- ERB
- Erubis
- Our own BlazeHtml.
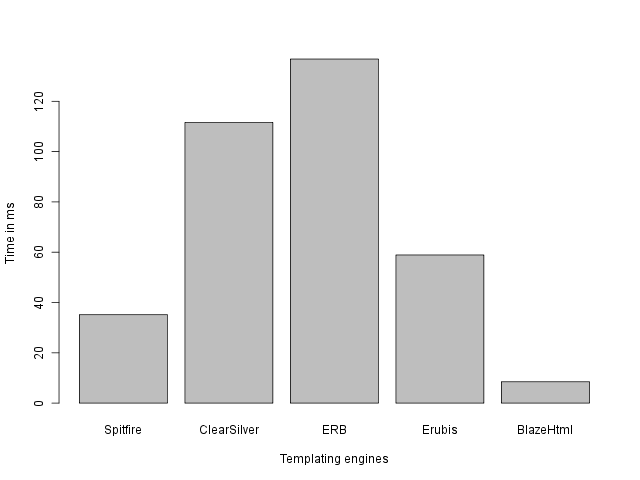
For the record, all benchmarks are run on a Intel CPU T2080 @ 1.73GHz. As you can see, BlazeHtml is quite fast. I also tried some other Haskell libraries. I will perform a more extensive benchmarking of the Haskell libraries available from Hackage in the near feature. For now, you can see some initial results here:
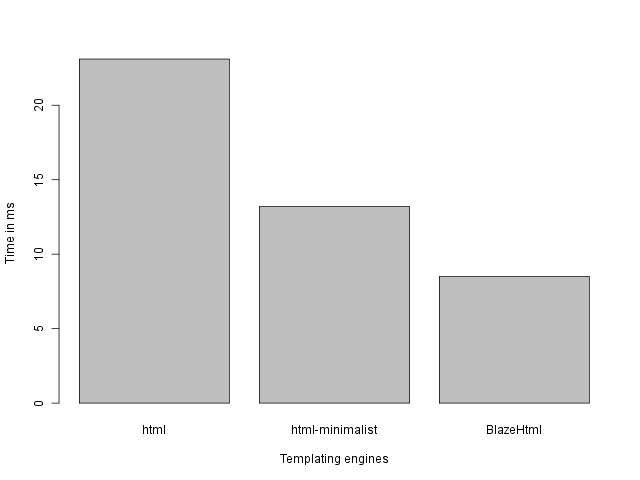
Although I have to say that this comparison is not quite fair. BlazeHtml produces encoded strings, where the other packages produce just strings (which still need to be encoded before sending them over the network).
The code used for these benchmarks can be found in our repo. Some benchmarks were implemented by the spitfire team, they can be found in their repo. I edited some of these benchmark so that all of them escape the table content, in order to make a more fair comparison.
Why is BlazeHtml fast
There are two design decisions underlying the speed that BlazeHtml features:
We avoid explicit intermediate data structures by using a continuation-passing style; i.e. our only intermediate data structures are closures, which are probably the best optimized data structures in a functional programming language like Haskell.
We copy each output byte at most once by using a mutable buffer encapsulated in a
Buildermonoid.
These two design decisions together with some well-chosen inlining resulted
already in a quite nice speed. What was missing then was fast writing of
individual bytes into a Builder: We were introducing too much overhead.
Every character was taken through an entire pipeline of functions that looked
more or less like
append . encode . escapeWhat I wanted is to have these operations executed on some sort of stream rather
than on every character. Originally, we were using the following function
(defined in Data.Binary.Builder) to create our Builder monoid:
singleton :: Word8 -> BuilderThis function was called for every byte, introducing a severe overhead. I was able to get significant speedups by defining the (manually fused) functions:
fromText :: Text -> Builder
fromUnescapedText :: Text -> Builder
fromString :: String -> BuilderThese functions were defined in Text.Blaze.Internal.Utf8Builder. They all rely
on a small patch to Data.Binary.Builder, exposing the following function:
-- | /O(n)./ A Builder from a raw write to a pointer.
--
fromUnsafeWrite :: Int -- ^ Number of bytes to be written.
-> (Ptr Word8 -> IO ()) -- ^ Function that does the write.
-> Builder -- ^ Resulting 'Builder'.As you can see from this signature, we have some code here that some people would consider “not elegant”. Those people include me. However, we must not forget that efficiency is our main goal. Besides, these functions are not exported to the end user.
The Future
So, that’s it for now. You can expect more updates from me in the feature, since I’ll be working on this project with great enthusiasm now that it has been accepted to Google Summer of Code 2010. Thanks to all the people who made this possible!
This blogpost was partly based on the notes I make while developing. These can be found here. I’d also like to thank Simon Meier for his continuous stream of feedback.