Text/UTF-8: Initial results
Published on July 10, 2011 under the tag haskell
What is this?
I’ve been working on the Data.Text library for my Google Summer of Code project under the wise supervision of Edward Kmett (but to be fair, Johan Tibell has also been helping me a lot, for which I am very grateful as well).
Some more context
Porting the Text library to use UTF-8 as internal encoding (instead of the currently used UTF-16) is a rather tricky task because there isn’t “one” representative benchmark: the results depend on:
- The nature of the program: read once, serve statically vs. do lots of in-memory manipulations vs. read, manipulate, write…)
- The language used: for example, ASCII only takes up half the number of bytes when comparing UTF-8 against UTF-16, whereas some East-Asian characters take up three bytes instead of two.
Tihs means that when a change is made, not all benchmark results change in the same direction. Hence, we aim for either making them faster, or keeping them as fast as they currently are, and have them use less memory.
On to the results!
For the record, the test files used are an ASCII text file of 58M and a russian file of 62M. Note that while they are of (more or less) the same size, the ASCII text is a lot longer when counting characters instead of bytes (about twice as long).
Uppercasing
The first program I benchmarked for this blogpost is a simple one which converts
a file to uppercase. Note the fact that the input and output needs to happen in
UTF-8 (which is usually the case), but that this doesn’t make such a big impact
as you might initially think: by using Stream Fusion, the UTF-16 version will
also read the input from the ByteString directly.
module Main where
import System.Environment (getArgs)
import qualified Data.ByteString as B
import qualified Data.Text as T
import qualified Data.Text.Encoding as T
main :: IO ()
main = do
(filePath : _) <- getArgs
text <- fmap T.decodeUtf8 $ B.readFile filePath
B.putStr $ T.encodeUtf8 $ T.toUpper text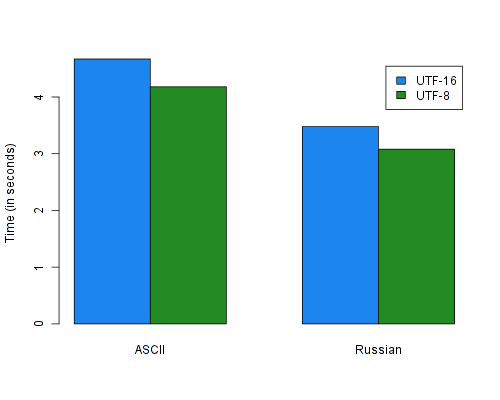
Word frequencies
Because Stream Fusion plays such an important role in the first benchmark, Johan
suggested I used another benchmark in which the Text values are used as keys
in a Map – that way, they are forced to be reified as an UTF-8 encoded array.
Word frequencies is a simple example of such a program; the next benchmark finds the most used word in a text (“the” for the English ASCII text and “и” for the Russian text).
import Data.List (foldl', maximumBy)
import Data.Map (Map)
import Data.Ord (comparing)
import System.Environment (getArgs)
import qualified Data.ByteString.Char8 as B
import qualified Data.Map as M
import qualified Data.Text as T
import qualified Data.Text.Encoding as T
import qualified Data.Text.IO as T
frequencies :: Ord a => [a] -> Map a Int
frequencies = foldl' (\m k -> M.insertWith (+) k 1 m) M.empty
top :: Map a Int -> a
top = fst . maximumBy (comparing snd) . M.toList
main :: IO ()
main = do
(filePath : _) <- getArgs
text <- fmap T.decodeUtf8 $ B.readFile filePath
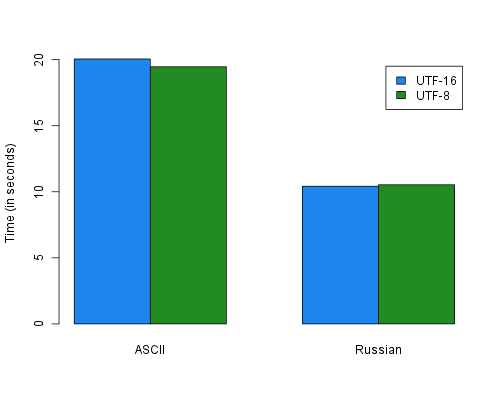
T.putStrLn $ top $ frequencies $ T.words $ T.toLower textThe results for this benchmark are very similar for both UTF-8 and UTF-16. This
is reasonable because I wrote a new Ord instance for Text which performs
better for medium-to-long Text values (e.g. more than 32 characters) but
slightly worse for small Text values, because there is the overhead of an
extra function call. This Ord instance is heavily used in the above benchmark,
because of the Map container – But these results indicate that there is no
real degradation here, so I can rejoice.
What’s next
There’s still lots of work to be done. In the next blogpost, I hope to talk about reduced memory usage and its implications.