The ZuriHac registration system
Published on September 3, 2019 under the tag haskell
Introduction
I am one of the organizers of ZuriHac, and last year, we hand-rolled our own registration system for the event in Haskell. This blogpost explains why we decided to go this route, and we dip our toes into its design and implementation just a little bit.
I hope that the second part is especially useful to less experienced Haskellers, since it is a nice example of a small but useful standalone application. In fact, this was more or less an explicit side-purpose of the project: I worked on this together with Charles Till since he’s a nice human being and I like mentoring people in day-to-day practical Haskell code.
In theory, it should also be possible to reuse this system for other events – not too much of it is ZuriHac specific, and it’s all open source.

Why?
Before 2019, ZuriHac registration worked purely based on Google tools and manual labor:
- Google Forms for the registration form
- Google Groups to contact registrants
- Google Sheets to manage the registrants, waitlist, T-Shirt numbers, …
Apart from the fact that the manual labor wasn’t scaling above roughly 300 people, there were a number of practical issues with these tools. The biggest issue was managing the waiting list and cancellations.
You see, ZuriHac is a free event, which means that the barrier to signing up for it is (intentionally and with good reason!) extremely low. Unfortunately, this will always result in a significant amount of people who sign up for the event, but do not actually attend. We try compensating for that by overbooking and offering cancellations; but sometimes it turns out to be hard to get people to cancel as well – especially if it’s hard to reach them.
Google Groups is not great for the purpose we’re using it for: first of all, attendees actually need to go and accept the invitation to join the group. Secondly, do you need a Google Account to join? I still don’t know and have seen conflicting information over the years. Anyway, it’s all a bit ad-hoc and confusing.
So one of the goals for the new registration system (in addition to reducing work on our side) was to be able to track participant numbers better and improve communication. We wanted to work with an explicit confirmation that you’re attending the event; or with a downloadable ticket so that we could track how many people downloaded this 1.
I looked into a few options (eventbrite, eventlama, and others…) but none of these ticked all the boxes: aside from being free (since we have limited budget). Some features that I wanted were:
- complete privacy for our attendees
- a custom “confirmation” workflow, or just being able to customize the registration flow in general
- and some sort of JSON or CSV export option
With these things in mind, I set out to solve this problem the same the way I usually solve problems: write some Haskell code.
How?
The ZuriHac Registration system (zureg) is a “serverless” application that runs on AWS. It was designed to fit almost entirely in the free tier of AWS; which is why I, for example, picked DynamoDB over a database that’s actually nice to use. We used Brendan Hay’s excellent and extensive amazonka libraries to talk to AWS.
The total cost of having this running for a year, including during ZuriHac itself, totaled up to 0.61 Swiss Francs so I would say that worked out well price wise!
There are two big parts to the application: a fat lambda 2 function that provides a number of different endpoints, and a bunch of command line utilities that talk to the different services directly.
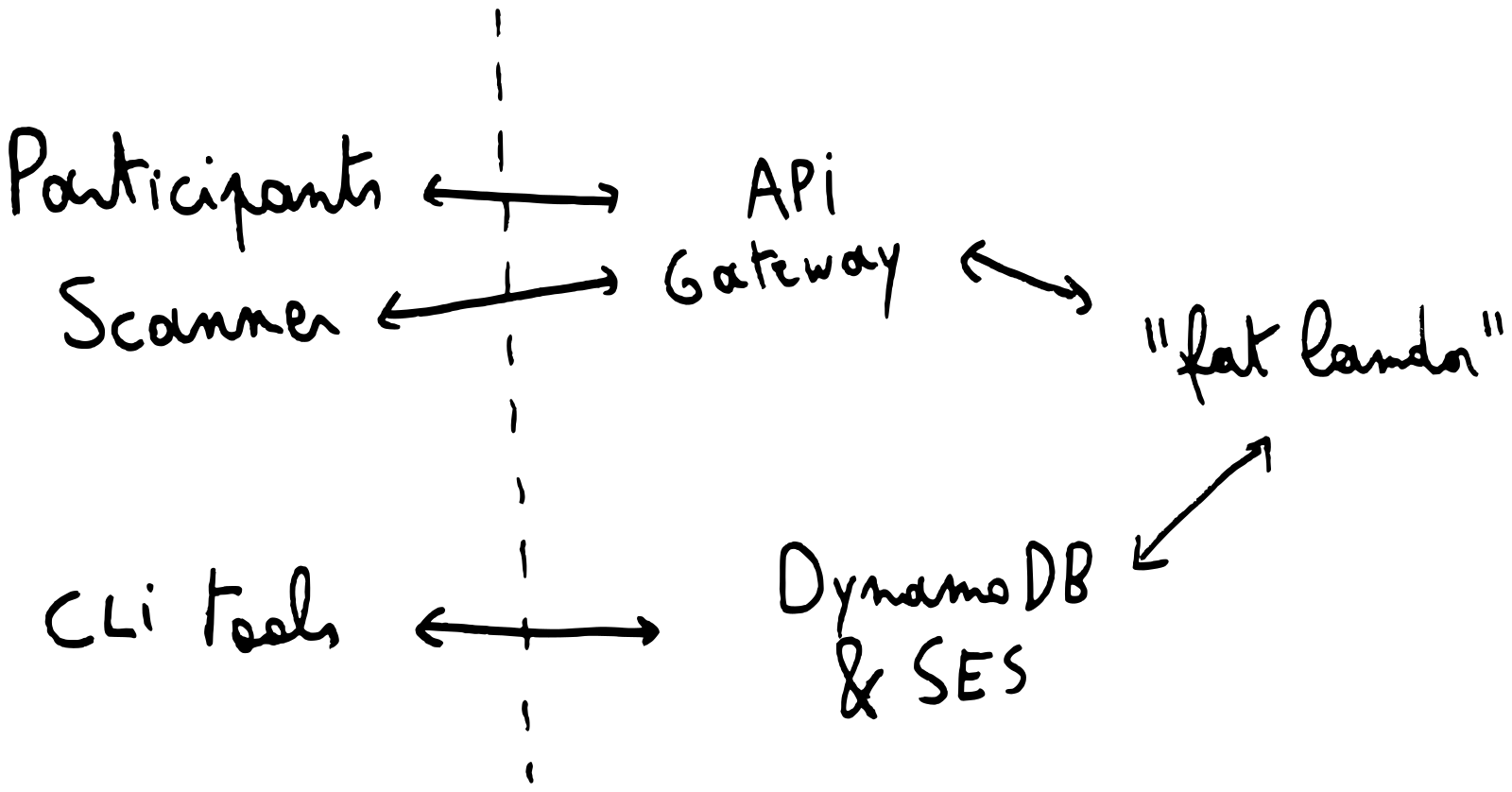
All these parts, however, are part of one monolithic codebase which makes it very easy to share code and ensure all behaviour is consistent – globally coherent as some would call it. One big “library” that has well-defined module boundaries and multiple lightweight “executables” is how I like to design applications in Haskell (and other languages).
Building and deploying
First, I’d like to go into how the project is built and compiled. It’s not something I’m proud of, but I do think it makes a good cookbook on how to do things the hard way.
The main hurdle is that we wanted want to run our Haskell code on Lambda, since this is much cheaper than using an EC2 instance: the server load is very bursty with long periods (days up to weeks) of complete inactivity.
I wrote a bunch of the zureg code before some Haskell-on-Lambda solutions popped up, so it is all done from scratch – and it’s surprisingly short. However, if I were to start a new project, I would probably use one of these frameworks:
Converting zureg to use of these frameworks is something I woulld like to look into at some point, if I find the time. The advantage of doing things from scratch, however, is that it serves the educational purposes of this blogpost very well!
Our entire serverless framework is currently contained in a single 138-line file.
From a bird’s eye view:
We define a docker image that’s based on Amazon Linux – this ensures we’re using the same base operating system and system libraries as Lambda, so our binary will work there.
We compile our code inside a docker container and copy out the resulting executable to the host.
We zip this up together with a python script that just forwards requests to the Haskell process.
We upload this zip to S3 and our cloudformation takes care of setting up the rest of the infrastructure.
I think this current situation is still pretty manageable since the application is so small; but porting it to something nicer like Nix is definitely on the table.
The database
The data model is not too complex. We’re using an event sourcing approach: this means that our source of truth is really an append-only series of events rather than a traditional row in a database that we update. These events are stored as plain JSON, and we can define them in pure Haskell:
And then we just have a few handwritten functions in the database module:
This gives us a few things for free; most importantly if something goes wrong we can go in and check what events led the user to get into this invalid state.
This code is backed by the eventful and eventful-dynamodb libraries, in addition to some custom queries.
The lambda
While our admins can interact with the system using the CLI tooling, registrants interact with the system using the webapp. The web application is powered by a fat lambda.
Using this web app, registrants can do a few things:
- Register for the event (powered by a huge web 1.0 form using digestive-functors);
- View their ticket (including a QR code generated by qrcode;
- Confirm their registration;
- Cancel their registration.
In addition to these routes used by participants, there’s a route used for ticket scans – which we’ll talk about next.
The scanning
Now that we have participant tickets, we need some way to process them at the event itself.
scanner.js is a small JavaScript tool that does this for us. It uses the device’s webcam to scan QR codes – which is nice because this means we can use either phones, tablets or a laptop to scan tickets at the event, the device just needs a modern browser version. It’s built on top of jsQR.
The scanner intentionally doesn’t do much processing – it just displays a full-screen video of the webcam and searches for a QR code using an external library. Once we get a hit for a QR code, we poll the lambda again to retrieve some information (participant name, T-Shirt size) and overlay that on top of the video.
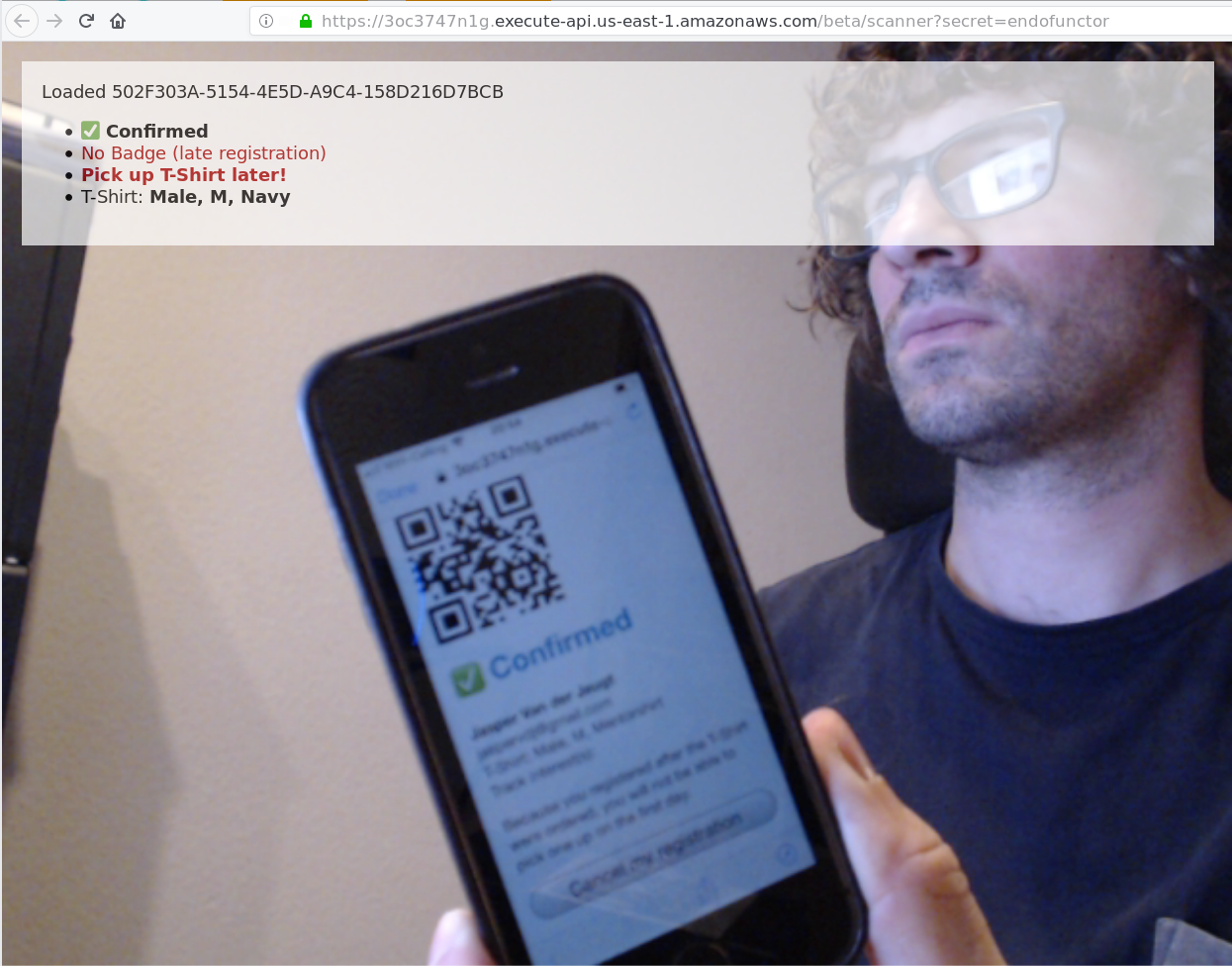
This is useful because now the people working at the registration desk can see, as demonstrated in the image above, that I registered too late and therefore should only pick up a T-Shirt on the second day.
What is next?
There is a lot of room for improvement, but the fact that it had zero technical issues during registration or the event makes me very happy. Off the top of my head, here are some TODOs for next years:
- We should have a CRON-style Lambda that handles the waiting list automation even further.
- It should be easier for attendees to update their information.
Other than that, there are some non-functional TODOs:
- Can we make the build/deploy a bit easier?
- Should we port zureg to use one of the existing Haskell-on-Lambda frameworks?
- I’m currently using somewhat fancy image scaling to get a sharp scaled up QR image, but this does not work if someone saves it on their phone – we should just do the scaling on the backend.
Any contributions in these areas are of course welcome!
Lastly, there’s the question of whether or not it makes sense for other events to use this. I discussed this briefly with Franz Thoma, one of the organizers of Munihac, who expressed similar gripes about evenbrite.
As it currently stands, zureg is not an off-the-shelf solution and requires some customization for your event – meaning it only really makes sense for Haskell events. On the other hand, there are a few people who prefer doing this over mucking around in settings dashboard that are hugely complicated but still do not provide the necessary customization.
I realize this is a bit creepy, and fortunately it turned out not to be necessary since we could do the custom confirmation flow.↩︎
In serverless terminology, it seems to common to refer to lambdas that deal with more than one specific endpoint or purpose as “fat lambdas”. I think this distracts from the issue a bit, since it’s more important to focus on how the code works and whether or not you can re-use it rather than how it is deployed – but coming from a functional programming perspective I very much enjoy the sound of “fat lambda”.↩︎