Caching in Hakyll: Long live Data.Binary!
Published on January 25, 2010 under the tag haskell
What is this about
Some experiences from trying to make Hakyll run faster. I explain some of the things I have tried, and some of the things that have failed, in the hope this could one day be helpful to other projects.
How much does speed matter in Hakyll
Before you implement any caching measures in any program, you try to estimate
what the speed gain will be. This is a heap profile from me generating this site
from scratch (so after a ./hakyll clean).
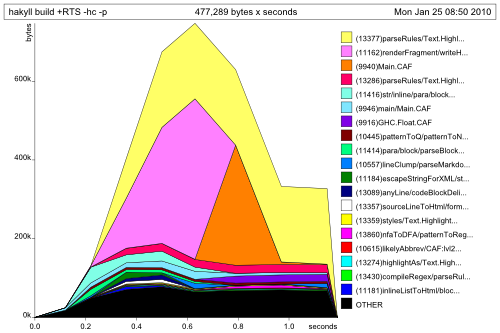
I am far from an expert at Haskell profiling, and this graph is a heap profile and not really a benchmark, but I think you can nonetheless see that the functions from Pandoc (seen here as the top yellow and pink blocks) are the “more heavy” ones. This makes sense, because rendering Pandoc markdown1 to html is not easy. The total time is under 2 seconds, but there are only a few blogposts on this site now. I’ve taken it to the test, copying a blogpost a hundred times, and the result was that the time taken rose linearly with the number of posts (hey, who would’ve expected that).
The thing is that we can’t simply “make pandoc faster”. Pandoc is a marvelous piece of software, and probably quite optimized. What we can do is try to call Pandoc less.
Simple timestamp checking
One “caching” technique used in Hakyll is simple timestamp checking. For
example, the projects page on my website is created from
two files: a projects.markdown file containing the content, and a default
template templates/default.html containing the header and footer of this
site. Now, Hakyll generates all of it’s files to the _site directory. So it
will perform a trivial timestamp test, and if _site/projects.html exists, and
is more recent than both projects.markdown and templates/default.html, we
don’t have to generate it again.
- good: If we edit
projects.markdown, only that file needs to be built again. - bad: If we edit
templates/default.html, all pages using this template need to be rebuilt. And as you can see, every page uses this template!
So the solution here would be to cache Pandoc results in the _cache directory.
Our code to load a page would then be something like:
valid <- check that the page is in _cache and more
recent than the original
if valid then return the result from the cache
else read and parse the page
store it in the cache
return itThis means that when we edit templates/default.html, we don’t have to render
every markdown file anymore, we can just fetch it from the cache. Now, how will
we implement this storing and fetching from the cache?
Rolling our own serializer (disclaimer: worst idea)
A simple markdown page has the following layout:
---
title: Foobar
--- sidebar
This is a _sidebar_.
---
# Title
- Item one.
- Item two.My first idea was to store this in the cache as
---
title: Foobar
--- sidebar
This is a <i>sidebar</i>.
---
<h1>Title</h1>
<ul>
<li>Item one.</li>
<li>Item two.</li>
</ul>So, we basically write it out in the same format, but with the rendered html, so we don’t need to call Pandoc anymore. This seemed like an okay idea to me, but I encountered some problems very quickly:
- It is not that easy to write it out in the same format.
- We need to watch out not to add
---lines in the html, or it will be read wrong when we fetch it from the cache. - It is still pretty slow to parse, because we want to check for the different
sections, like the
sidebarin this example.
I eagerly ran the test with a hundred blogposts again, waited and… well, to be fair, I didn’t even finish implementing this (I implemented a part of it, but it was still buggy). So, in short, this was a pretty bad idea: not easy to implement, and it was slow.
deriving (Show, Read)
Haskell provides automatic serialization using the Show and Read
typeclasses. This seemed like an appealing option to me, also because of the
fact it is very trivial to implement. I just made the Page2 type an
instance:
data Page = Page Context
deriving (Show, Read)I eagerly ran the test with a hundred blogposts again, waited and… nothing.
Well, nearly nothing. I knew the automatic Read class is not that fast for
large datatypes, but I hadn’t expected it to be so slow in this particular case.
From 60 seconds3 without caching, it now took 58 seconds. Great, just great.
But my options weren’t exhausted yet. I had recently read about the supposedly
great Data.Binary library, so I thought I’d
give it a try.
Data.Binary
It turned out adding an instance for Binary Page was nearly as easy as adding
the Show and Read instances. Since Data.Binary provides instances for
lists, tuples and strings, we can also serialize maps using the toAscList and
fromAscList functions. Put short, I was able to make the Page type
serializable using three lines of code:
instance Binary Page where
put (Page context) = put $ M.toAscList context
get = liftM (Page . M.fromAscList) getI eagerly ran the test with a hundred blogposts again, waited and… profit! From previously taking 60 seconds, it now took only 15 seconds!
Conclusions
Data.Binary rocks. I am now using it for a lot more than Pages: I also use
it to cache tags and templates. But this shows the initial idea and how I got
to try it out. I hope this blogpost encourages people to use it, it’s really
worth the effort4.
I mostly talk about Pandoc markdown in this post, but it really applies to all formats supported by Pandoc.↩︎
The
Contexttype seen there is basically aMap String String.↩︎60 seconds after a
./hakyll clean. This seemed the most fair benchmark, and caching would play a role here, since manyPages were accessed multiple times: for the tags, for the post list, for the posts themselves…Without a
./hakyll clean, well, it’s very fast.↩︎The words “worth the effort” might not be chosen well, since the “effort” here comes down to adding 3 lines of code…↩︎