Text/UTF-8: Studying memory usage
Published on August 9, 2011 under the tag haskell
What is this?
This blogpost continues where the previous one left off. Again, I study the performance of an application using the Data.Text library intensively. The difference is that this blogpost focuses almost exclusively on the memory usage of the resulting application.
The application used is a simple document store. Clients can store documents per ID, and retrieve document ID’s based on terms in the document. This blogpost is written in Literate Haskell, feel free to grab the raw version.
We use the OverloadedStrings language extension for general prettiness…
{-# LANGUAGE OverloadedStrings #-}And then we have a whole lot of imports which you can skim right through.
import Data.Char (isPunctuation)
import Data.List (foldl')
import Data.Monoid (mconcat)
import Control.Applicative ((<$>))
import Control.Concurrent.MVar (MVar, modifyMVar_, newMVar, readMVar)
import Control.Monad.Reader (ReaderT, ask, runReaderT)
import Control.Monad.Trans (liftIO)
import Data.Maybe (fromMaybe)We will stick with simple Map and Set types for this benchmark.
import Data.Map (Map)
import Data.Set (Set)
import Data.Text (Text)
import qualified Data.ByteString.Char8 as BC
import qualified Data.ByteString.Lazy as BL
import qualified Data.Map as M
import qualified Data.Set as S
import qualified Data.Text as T
import qualified Data.Text.Encoding as TWe’ll use BlazeHTML for some simple HTML rendering…
import Text.Blaze (Html, toHtml)
import Text.Blaze.Renderer.Utf8 (renderHtml)
import qualified Text.Blaze.Html5 as H… and Snap as web application layer.
import Snap.Types ( Snap, getParam, getRequestBody, modifyResponse, route
, setContentType, writeLBS
)
import Snap.Http.Server (httpServe, defaultConfig)The pure logic
Let’s first write down the pure logic of our web application. When we receive a
document from a client, we want to extract the terms (i.e, words) used in the
document. This is why we have the tokenize function:
tokenize :: Text -> [Text]
tokenize =
filter (not . T.null) . map stripPunctuation . T.words . T.toLower
where
-- | Remove leading and trailing punctuation marks from a token
stripPunctuation = T.dropWhileEnd isPunctuation . T.dropWhile isPunctuationWe’ll use a simple type alias for the document store. For our benchmark, we
simply need a mapping from terms to document ID’s, so that’s exactly what we’ll
represent using a Map.
type Store = Map Text (Set Int)And finally, we need to be able to at least add a new document to the Store.
The following function takes care of that, tokenizing the document and adding
the ID under each token in the Map.
addDocument :: Int -> Text -> Store -> Store
addDocument id' doc store = foldl' insert store $ tokenize doc
where
insert s t = M.insertWith' S.union t (S.singleton id') sThe web logic
Next up is some logic code for the web application layer. We first define the type of our application:
type App = ReaderT (MVar Store) SnapThat is, in addition the features which Snap provides, we also need access to
a shared Store. All of our web controllers have this type: let’s look at the
controller which adds a document. The function is fairly straightforward, it
fetches the document ID and body, and adds it using modifyMVar_. Lastly, it
also shows a response to the client (we define the blaze auxiliary function
later).
documentAdd :: App ()
documentAdd = do
Just id' <- fmap (read . BC.unpack) <$> getParam "id"
doc <- T.decodeUtf8 . strict <$> getRequestBody
mvar <- ask
liftIO $ modifyMVar_ mvar $ return . addDocument id' doc
blaze $ documentView doc
where
strict = mconcat . BL.toChunksWe also want to be able to query the documents in our store. This isn’t hard at
all, we can simply look in the Map to find the documents associated with the
given query.
documentQuery :: App ()
documentQuery = do
store <- liftIO . readMVar =<< ask
query <- fmap T.decodeUtf8 <$> getParam "query"
let results = fromMaybe S.empty $ flip M.lookup store =<< query
blaze $ resultsView resultsHere, we have the auxiliary blaze function which is used to send some HTML to
the client.
blaze :: Html -> App ()
blaze html = do
modifyResponse $ setContentType "text/html; charset=UTF-8"
writeLBS $ renderHtml htmlThe web views
We also define some “templates” in order to show the different values to the client. They are given here mostly for completeness.
documentView :: Text -> Html
documentView = H.p . toHtmlresultsView :: Set Int -> Html
resultsView = H.ul . mconcat . map (H.li . toHtml) . S.toListGlueing it all together
What remains is some routing and a main function to glue it all together.
app :: App ()
app = route
[ ("/document/query/:query", documentQuery)
, ("/document/:id", documentAdd)
]main :: IO ()
main = do
mvar <- newMVar M.empty
httpServe defaultConfig (runReaderT app mvar)Results
Next up is running it! I ran the application twice, once using the current version of Text, and once using my UTF-8 based port. A client was simulated which sent a large volume of twitter data in a variety of languages to the server. The following graph represents memory usage over time:
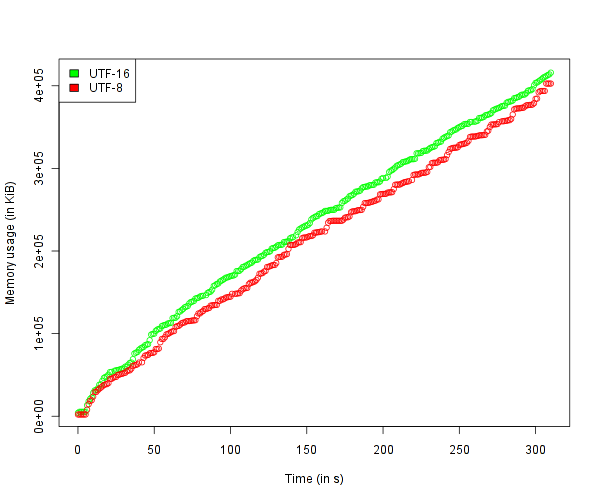
Conclusions
While there is a very clear difference, it isn’t as large as I first suspected. This is caused by a number of reasons:
- we use a Text value per token in the document. There is an additional 6 words per value, causing a non-negligible overhead for the relatively small tokens;
- a lot of memory is taken up by
Set Intas well; - the internal structure of the
Mapalso takes up 6 words per item.
That being said, I think the difference shows that UTF-8 clearly has some benefits over UTF-16 in many situations. I’m looking forward to discussing more of the possible advantages and disadvantages… perhaps at CamHac?