Lazy Sort: Counting Comparisons
Published on September 17, 2020 under the tag haskell
Introduction
Haskell’s laziness allows you to do many cool things. I’ve talked about searching an infinite graph before. Another commonly mentioned example is finding the smallest N items in a list.
Because programmers are lazy as well, this is often defined as:
smallestN_lazy :: Ord a => Int -> [a] -> [a]
smallestN_lazy n = take n . sortThis happens regardless of the language of choice if we’re confident that the list will not be too large. It’s more important to be correct than it is to be fast.
However, in strict languages we’re really sorting the entire list before taking the first N items. We can implement this in Haskell by forcing the length of the sorted list.
smallestN_strict :: Ord a => Int -> [a] -> [a]
smallestN_strict n l0 = let l1 = sort l0 in length l1 `seq` take n l1If you’re at least somewhat familiar with the concept of laziness, you may
intuitively realize that the lazy version of smallestN is much better since
it’ll only sort as far as it needs.
But how much better does it actually do, with Haskell’s default sort?
A better algorithm?
For the sake of the comparison, we can introduce a third algorithm, which does
a slightly smarter thing by keeping a heap of the smallest elements it has seen
so far. This code is far more complex than smallestN_lazy, so if it performs
better, we should still ask ourselves if the additional complexity is worth it.
smallestN_smart :: Ord a => Int -> [a] -> [a]
smallestN_smart maxSize list = do
(item, n) <- Map.toList heap
replicate n item
where
-- A heap is a map of the item to how many times it occurs in
-- the heap, like a frequency counter. We also keep the current
-- total count of the heap.
heap = fst $ foldl' (\acc x -> insert x acc) (Map.empty, 0) list
insert x (heap0, count)
| count < maxSize = (Map.insertWith (+) x 1 heap0, count + 1)
| otherwise = case Map.maxViewWithKey heap0 of
Nothing -> (Map.insertWith (+) x 1 heap0, count + 1)
Just ((y, yn), _) -> case compare x y of
EQ -> (heap0, count)
GT -> (heap0, count)
LT ->
let heap1 = Map.insertWith (+) x 1 heap0 in
if yn > 1
then (Map.insert y (yn - 1) heap1, count)
else (Map.delete y heap1, count)So, we get to the main trick I wanted to talk about: how do we benchmark this, and can we add unit tests to confirm these benchmark results in CI? Benchmark execution times are very fickle. Instruction counting is awesome but perhaps a little overkill.
Instead, we can just count the number of comparisons.
Counting comparisons
We can use a new type that holds a value and a number of ticks. We can increase the number of ticks, and also read the ticks that have occurred.
data Ticks a = Ticks {ref :: !(IORef Int), unTicks :: !a}
mkTicks :: a -> IO (Ticks a)
mkTicks x = Ticks <$> IORef.newIORef 0 <*> pure x
tick :: Ticks a -> IO ()
tick t = IORef.atomicModifyIORef' (ref t) $ \i -> (i + 1, ())
ticks :: Ticks a -> IO Int
ticks = IORef.readIORef . refsmallestN has an Ord constraint, so if we want to count the number of
comparisons we’ll want to do that for both == and compare.
instance Eq a => Eq (Ticks a) where
(==) = tick2 (==)
instance Ord a => Ord (Ticks a) where
compare = tick2 compareThe actual ticking code goes in tick2, which applies a binary operation and
increases the counters of both arguments. We need unsafePerformIO for that
but it’s fine since this lives only in our testing code and not our actual
smallestN implementation.
tick2 :: (a -> a -> b) -> Ticks a -> Ticks a -> b
tick2 f t1 t2 = unsafePerformIO $ do
tick t1
tick t2
pure $ f (unTicks t1) (unTicks t2)
{-# NOINLINE tick2 #-}Results
Let’s add some benchmarking that prints an ad-hoc CSV:
main :: IO ()
main = do
let listSize = 100000
impls = [smallestN_strict, smallestN_lazy, smallestN_smart]
forM_ [50, 100 .. 2000] $ \sampleSize -> do
l <- replicateM listSize randomIO :: IO [Int]
(nticks, results) <- fmap unzip $ forM impls $ \f -> do
l1 <- traverse mkTicks l
let !r1 = sum . map unTicks $ f sampleSize l1
t1 <- sum <$> traverse ticks l1
pure (t1, r1)
unless (equal results) . fail $
"Different results: " ++ show results
putStrLn . intercalate "," . map show $ sampleSize : nticksPlug that CSV into a spreadsheet and we get this graph. What conclusions can we draw?
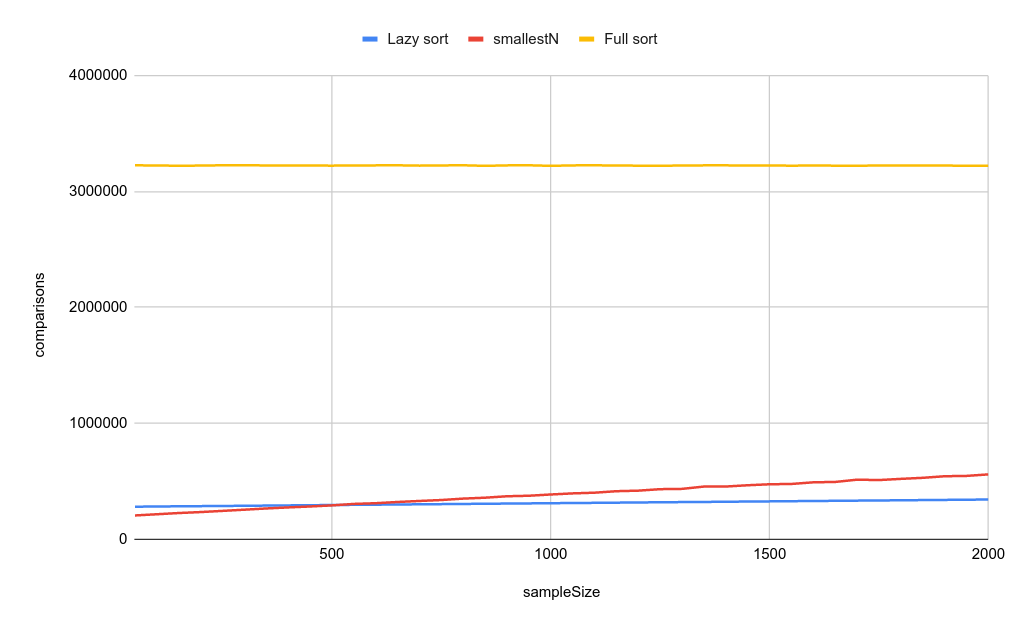
Clearly, both the lazy version as well as the “smart” version are able to avoid a large number of comparisons. Let’s remove the strict version so we can zoom in.
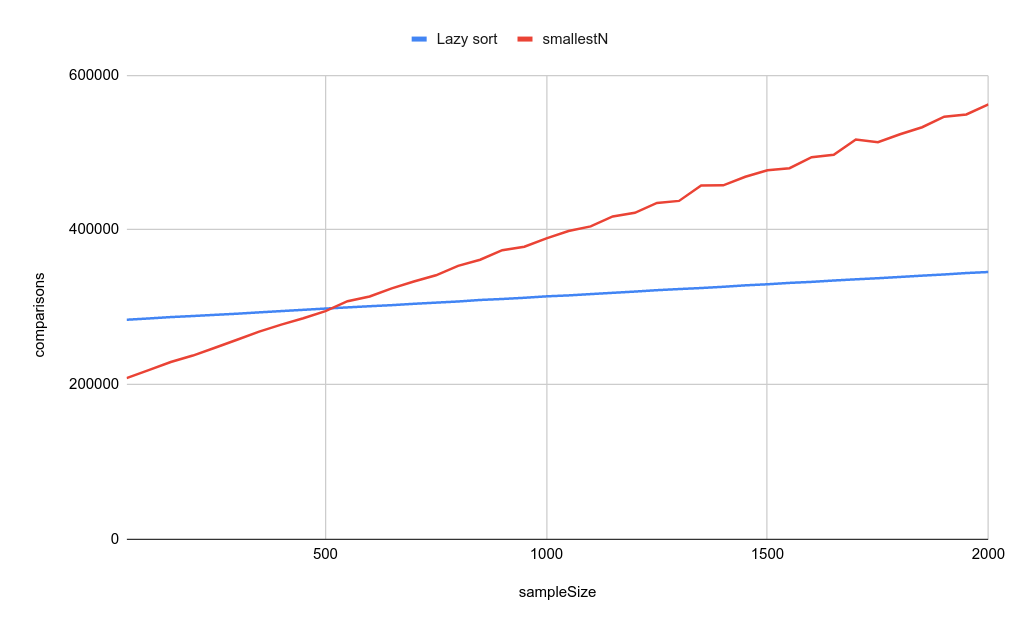
What does this mean?
If the
sampleSizeis small, the heap implementation does less comparions. This makes sense: even if treatsortas a black box, and don’t look at it’s implementation, we can assume that it is not optimally lazy; so it will always sort “a bit too much”.As
sampleSizegets bigger, the insertion into the bigger and bigger heap starts to matter more and more and eventually the naive lazy implementation is faster!Laziness is awesome and
take N . sortis absolutely the first implementation you should write, even if you replace it with a more efficient version later.Code where you count a number of calls is very easy to do in a test suite. It doesn’t pollute the application code if we can patch in counting through a typeclass (
Ordin this case).
Can we say something about the complexity?
The complexity of
smallestN_smartis basically inserting into a heaplistSizetimes. This gives usO(listSize * log(sampleSize)).That is of course the worst case complexity, which only occurs in the special case where we need to insert into the heap at each step. That’s only true when the list is sorted, so for a random list the average complexity will be a lot better.
The complexity of
smallestN_lazyis far harder to reason about. Intuitively, and with the information thatData.List.sortis a merge sort, I came to something likeO(listSize * max(sampleSize, log(listSize))). I’m not sure if this is correct, and the case with a random list seems to be faster.I would be very interested in knowing the actual complexity of the lazy version, so if you have any insights, be sure to let me know!
Update: Edward Kmett corrected me: the complexity of
smallestN_lazyis actuallyO(listSize * min(sampleSize, listSize)), withO(listSize * min(sampleSize, log(listSize))in expectation for a random list.
Thanks to Huw Campbell for pointing out a bug
in the implementation of smallestN_smart – this is now fixed in the code
above.
Appendix
Helper function: check if all elements in a list are equal.
equal :: Eq a => [a] -> Bool
equal (x : y : zs) = x == y && equal (y : zs)
equal _ = True